Work with Mark: Old System Designs
So Mark d'Inverno and I worked on quite a few different systems. They all differed but the main goal remained fix: we wanted a responsive music system built from a multi-agent system approach.
The first ideas circled around a multi-agent band.
We originally considered the idea of a multi-agent band, but this was soon dismissed because of the complexity involved with feedback. How does one agent perceive the output of another agent; in effect how do we give that agent ears? The only possibility is to allow one agent to look at some portion of the code that is being generated but it is not clear how you could do this with any semblance of replicating the real-life improvising group of musicians.
Some questions that arose in considering how to build such a band. How aware should the agents be of its fellow musicians? What interplay do we allow between musicians and how to we facilitate this? Should there be one agent per style/piece/genre or is the agent an all-round virtuous that can play in different styles/genres? Does an agent know what notes to play by itself or is it handed a score and told what and when to play? Is the agent itself responsible for different manipulations and effects to the sound it generates, or are there other agents deciding this? Perhaps, there is a project for someone else out there?
We abandoned that and tried to simplify a bit. The design we came up with next is sketched out here...
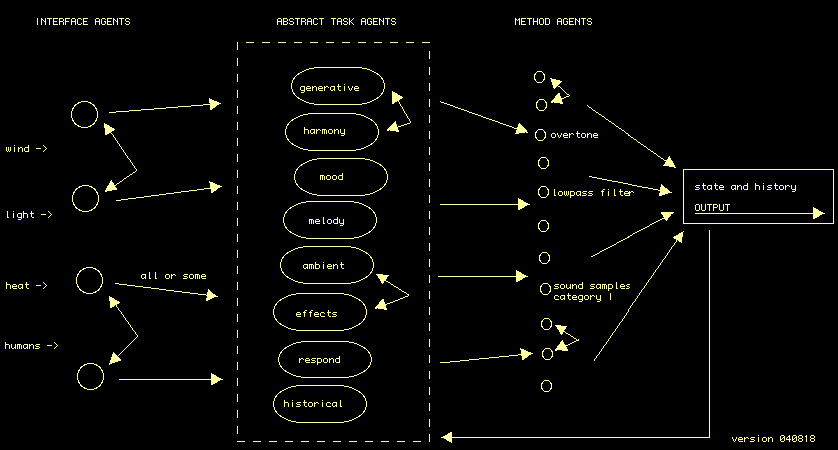
and our ideas around its design was as follows...
A basic design
In order to address some of the issues and motivations outlined in this document we propose a multi-agent architecture with the following design elements.
1. It would be responsive to the external environment: time, date, day, season, temperature, humidity, sunlight, individual and collective human actions, rainfall, wind, the ambient sound level of what is happening (should be able to record this sound and play it back).
2. It would not be beat-based per se, but there might be rhythmic elements. Rhythm more seen as an important parameter along with others - not being the predominant one.
3. We are interested in exploring the notion of harmony and melody and how this relates to the emotional state of a user. Naturally, we also want to build something aesthetically pleasant.
4. We will employ a multi-agent system architecture to manage the different elements that can take place in a music system. Agents will negotiate and compromise for control over modifying parameters and using various hard-coded methods, and hence the systems overall output.
Interface agents will monitor some aspects of the environment and may communicate with each other. We will build one agent for each different environmental parameter we wish to measure. It may be that these agents are requested to look for certain things in the environment. For example the human activity agent might be asked to look out for a certain pattern of behaviour or to notify when the number of humans goes above a certain threshold. In other words these agents are more than sensors and can change what they are trying to perceive after receiving information from other agents.
Abstract task agents will be able to collect information from some or all of the interface agents. But they will have different features and goals and will therefore need to negotiate to resolve conflicts. For example, they might agree to take it in turns to chose when there is a conflict over what should happen to the output next.
We have identified several possible abstract task agents
1. A responsive agent that wishes to respond to external stimulus
2. A control agent who wants to try and provide a user with a desired or intended response
3. A Generative agent who will try to negate and provide counter-intuitive or meaningless responses, and also try to kick-start or trigger events even when there is no external stimulus currently taking place.
4. A melody agent who tries to create an aesthetic piece giving its understanding of traditional harmony and melody. It may work with the generative agent in many cases, asking for input and denying or accepting the ideas based on its own rules about what is appropriate.
5. We could have a harmonising agent that attempts to provide harmonisation of a particular piece too?
6. A mood agent wants to resonate environment mood - both 'get' and 'set'.
7. A historical agent wants to repeat things happened before and maybe start record sounds when there are drastic changes in the interface agents and so on.
These agents all have a notion of the current state. These then negotiate to call the various methods at its disposal. The method agents who have very specific abilities such as a low pass filter, changing harmonic density, playing sound samples of a specific category, adding overtones. As these methods have an effect on the suitability of each other they should negotiate first. These agents do not have a notion of the current state only some idea of their possible effects on each other. We believe there is a relationship between mood and method and we will try and harness this to build a sound device which has the basic attributes we described at the beginning of this document.
Towards a Prototype System
The Interface Agents
One restriction to put upon our system is to quantise time and let the interface agents work at three distinct time scales; short, medium and long. This restriction would be general for all agents interfacing the external environment.
For example, the agent aware of light could keep abrupt changes in its short-time memory e.g. someone flicks the light switch or passes by a window, the amount of daylight is stored in its medium-term memory and last the agent's long-time memory keeps track of seasonal changes, full moon etc.
The agent responsible for monitoring human activity should work in a similar way. Short-term would here be gestures, medium: amount of people and their activity in the environment and long-term memory is general use and popularity of the system, people's habits, change of office hours etc.
The temporal agent might in its slot for short-time memory keep hours, minutes and seconds. Medium-scale memory could contain time of day and what weekday (Sunday-morning/Monday-lunch/Friday-night) and long-term the time of year (winter/late-spring/early-autumn...) Wind, heat, humidity and the rest of the interface agents would all work in a similar way.
Internally these different scales would poll each other for information, averaging and calculating their respective summary short-medium-long. For medium and long-term memory log files will be written to disk for backup. Depending on which mappings we want to do and what results we want from the interface part of the system, the agents here need to communicate with each other in different ways. E.g. if we need some musical parameter to be changed (or action to be taken) when the room is crowded and hot, we could implement that to the human interface agent. It would utilise the motion tracking sensor to see if there are - presently - many people about, look in its medium-term memory to figure out if there's a tendency/crowd gathering and also communicate with the heat agent to see if it has similar input.
There can also be a direct one-to-one mapping between the agent's discrete points in time and some musical parameters. How many and which parameters we choose to control here will decide how directly responsive the system output will be. Possibly the degree of direct mapping (mostly concerning short-time) can be varied over time. For a first-time user it might be a good thing if the direct feedback is slightly exaggerated. He/she would like to get instant gratification to become comfortable with that the system really is working, alive and reacting. But after time - to keep interest up - other things could become more important like the combination of sensors or 'musical' music progression. These direct mappings could also be present all the time but scaled up/down and mixed with other controllers.
[...]
The actual data from the sensors can be handled in two different ways and hopefully we can try out a combination of both. The first way would be to automatically normalise incoming values to a range of say 0.0-1.0. So if the program detects a peak greater than the previous maximum peak, it will replace the old with the new value and start using that as a scaling factor. This will make the sensors adapt to any environment and its extreme conditions.
Another way of handling the input would be to assume a probable range for each sensor and just clip extreme values. The advantage here is that the system won't be less responsive over time (eg. some vandal screams in the microphone and sets the peak level to an unreasonable value - making the microphone non-sensitive to subtle background noise amplitude later on). The drawback is that the system needs to be tuned for each new location and that over a longer period of time. The ideal is a combination of the two that does adapt directly but also falls back to some more reasonable default or average if someone messes with it or something breaks (i.e. will disregard totally unlikely extreme peaks).
After normalisation we will scale the inputs from the different sensors. This will allow us to tune our system and change the weight of importance for each interface agent. But to begin with we'll just assume equal power for all sensors.
It is our aim to build a flexible and modular system that can be installed in many different environments/locations and with changing budgets. So if sensors aren't present, breaks or have to be exchanged for some other type, we only instantiate a new interface agent reading from that particular sensor or device. The system should run with any number of interface agents and any number of sensors.
We also see the possibility of adding, to the list of interface agents, a few 'proxy' interface agents. These would work for any device or stream of data and would look for abrupt changes, tendencies and overall activity (at three discrete times). The users would decide what to read from. Examples of input for these proxies could be home-built sensors that the users bring with them and plug into a slot, some device or installation already present nearby the location where our system is set up or maybe stock market data downloaded from the net. Having these proxies would make each installation unique and site-specific also on the hardware input side.
Implementation of the interface agents will be done by having an abstract superclass (pseudo code below):
InterfaceAgent { //abstract class
short {
//method looking for quick changes like gestures and transients
}
medium {
//method using this.short to calculate tendencies
}
long {
//method using this.medium to find out about long-term use and overall activity
}
}
Then the actual interface agent classes will all inherit behaviour from this superclass.
Wind : InterfaceAgent
Light : InterfaceAgent
Humans: InterfaceAgent
Proxy : InterfaceAgent
etc.
If time permits we'd also like to try to implement an agent that listens to the output of the system itself in an aesthetic way. It should evaluate the resulting music as groovy, soft, good, bad or less interesting. Machine listening is of course a huge project in itself but some rough presumptions could be done with the help of the other interface agents. A change in the music that for instance instantly empties the room of people should be considered appropriate. So there's already the microphone(s) listening to the sound output in different ways (amplitude, pitched sounds) but a more intelligent analysis of the resulting music would be a good thing that'd boost the complexity of the whole system by introducing yet more feedback.
The Abstract Task Agents and Method Agents
How to implement a task agent like mood? Where will the rules reside defining an emotion like happiness - in each of the method agents or within the task agent itself - or both? Below are two suggested implementations with corresponding bare-bone sounding examples.
1. Method agents are responsible for how to best be happy/sad.
In this example the method agents know themselves how to best reflect an emotion. E.g. lowpass agent understands the message 'happy' (coming from the task agent) and reacts to that by increasing the cutoff frequency 300 Hz. Likewise a 'sad' message would decrease the cutoff frequency by 300. Another rule could be a melody agent that, when receiving a 'happy' message, changes its currently playing melody to a major key and raises its tempo a little.
Simplest possible sounding example written in SuperCollider:
Starting out with three class definitions:
MethodAgent { //abstract superclass
var >synth;
*new { arg synth;
^super.new.synth_(synth);
}
update { arg param, value;
synth.set(param, value); //send parameters to the synth
}
}
Mlowpass : MethodAgent { //lowpass agent subclassing MethodAgent
var freq= 700;
happy {
freq= (freq+300).clip(100, 9000); //rule 1
this.update(\freq, freq);
}
sad {
freq= (freq-300).clip(100, 9000); //rule 2
this.update(\freq, freq);
}
}
Mmelody : MethodAgent { //melody agent subclassing MethodAgent
var third= 64, rate= 2;
happy {
third= 64; //rule 3
rate= (rate/0.9).clip(0.1, 10); //rule 4
this.update(\third, third.midicps);
this.update(\rate, rate);
}
sad {
third= 63; //rule 5
rate= (rate*0.9).clip(0.1, 10); //rule 6
this.update(\third, third.midicps);
this.update(\rate, rate);
}
}
In the above code rule 1 says: when happy - increase lowpass cutoff frequency by 300 but restrain values between 100 and 9000. Rule 3 would be: when happy - set the third scale position of the melody to be a major third. Rule 6: when sad- decrease melody tempo 10% but restrain values to between 0.1 and 10 (beats-per-second).
To try it out we first need to define two synths - one playing a lowpass filter and another one playing a simple melody.
s.boot; //start the SuperCollider sound server
a= SynthDef(\lowpass, {arg freq= 700; ReplaceOut.ar(0, LPF.ar(In.ar(0), freq))}).play(s);
b= SynthDef(\melody, {arg third= 329.63, rate= 2; Out.ar(0, Saw.ar(Select.kr(LFNoise0.kr(rate, 1.5, 1.5), [60.midicps, third, 67.midicps]), 0.1))}).play(s);
Then we create our two task agents.
x= Mlowpass(a); //create an abstract task agent and pass in a synth that plays a lowpass filter
y= Mmelody(b); //create an abstract task agent and pass in a synth that plays a simple melody
The actual mood messages are then sent in the following manner (imagine this done from the mood agent):
x.happy; y.happy; //send message 'happy' to both task agents
x.sad; y.sad; //send message 'sad' to both task agents
This design will make the task agents less bloated and it will be easy to change, add or remove method agents. The mood agent will just tell all available method agents to become happy and it can then focus on negotiation with other task agents.
2. Task agent is responsible for how to best be happy/sad.
This is exactly the same code example as above but rewritten to gather all our rules defining happy and sad inside the mood agent. First four new class definitions:
AbstractTaskAgent {
var >lpass, >melody;
*new { arg lpass, melody;
^super.new.lpass_(lpass).melody_(melody);
}
}
Mood : AbstractTaskAgent { //mood agent subclassing AbstractTaskAgent
happy {
lpass.freq= (lpass.freq+300).clip(100, 9000); //rule 1
melody.third= 64; //rule 3
melody.rate= (melody.rate/0.9).clip(0.1, 10); //rule 4
}
sad {
lpass.freq= (lpass.freq-300).clip(100, 9000); //rule 2
melody.third= 63; //rule 5
melody.rate= (melody.rate*0.9).clip(0.1, 10); //rule 6
}
}
Mlowpass2 : MethodAgent { //different lowpass agent subclassing MethodAgent
var <freq= 700;
freq_ { arg val;
this.update(\freq, val);
}
}
Mmelody2 : MethodAgent { //different melody agent subclassing MethodAgent
var <third= 64, <rate= 2;
third_ { arg val;
this.update(\third, val.midicps);
}
rate_ { arg val;
this.update(\rate, val);
}
}
Here is the same code as above for defining two synths.
s.boot; //start the supercollider sound server
a= SynthDef(\lowpass, {arg freq= 700; ReplaceOut.ar(0, LPF.ar(In.ar(0), freq))}).play(s);
b= SynthDef(\melody, {arg third= 329.63, rate= 2; Out.ar(0, Saw.ar(Select.kr(LFNoise0.kr(rate, 1.5, 1.5), [60.midicps, third, 67.midicps]), 0.1))}).play(s);
And this is how the mood agent is set up.
z= Mood(Mlowpass2(a), Mmelody2(b));
Last we send the messages to the mood agent like this:
z.happy;
z.sad;
Here method agents are very simple and only does what told. They can return their state and change the sound that they're in control of and that is it. It is the mood agent that knows what happiness means and will direct the methods agents to do certain things.
A good thing with this design is that the rules defining happiness are all in one place and it would be possible to write different versions of the mood agent that implements happiness in different ways. One drawback would be that for any change to the method agents, we would have to update and rewrite parts of the mood class.
Presently it seems like suggestion number two would be the design most suitable for our needs. This would mean that crosstalk between method agents isn't needed anymore as suggested in version one (see sketch#1). Conflicting or overlapping methods are rather dealt with by the task agents as they know which actions to take to come up with the desired result. On the other hand the method agents need to be able to report their state back to the method agents and also be intelligent enough to take their own actions e.g. telling when certain tasks are finished.